Apa itu parser?
Dalam teknologi komputer, parser adalah program yang biasanya menjadi bagian dari sebuah compiler. Parser menerima masukan berupa instruksi program sumber secara berurutan, perintah online interaktif, tag markup, atau antarmuka lain yang sudah didefinisikan.
Parser akan memecah input yang diterima menjadi bagian-bagian seperti kata benda (objek), kata kerja (metode), dan atribut atau opsinya. Setelah itu, bagian-bagian tersebut akan diproses oleh komponen pemrograman lainnya, misalnya bagian lain dari compiler. Parser juga bisa mengecek apakah semua input yang dibutuhkan sudah tersedia.
Bagaimana cara kerja parsing?
Parser merupakan program yang jadi bagian dari compiler, dan proses parsing sendiri adalah bagian dari tahap kompilasi. Parsing terjadi pada tahap analisis dalam proses kompilasi.
Saat parsing, kode yang diambil dari preprocessor akan dipecah menjadi bagian-bagian kecil dan dianalisis supaya bisa dipahami oleh perangkat lunak lain. Parser melakukannya dengan membangun struktur data dari potongan-potongan input tersebut.
Secara lebih detail, seseorang menulis kode dalam bahasa yang bisa dibaca manusia, seperti C++ atau Java, lalu menyimpannya dalam file teks. Parser mengambil file teks itu sebagai input dan memecahkannya agar bisa diterjemahkan di platform target.
Parser terdiri dari tiga komponen yang masing-masing menangani tahap berbeda dalam proses parsing. Tiga tahap tersebut adalah:
Tahap 1: Analisis leksikal
Analyzer leksikal — atau scanner — mengambil kode dari preprocessor dan memecahnya menjadi bagian-bagian kecil. Ia mengelompokkan input kode menjadi urutan karakter yang disebut *lexeme*, dan tiap lexeme akan cocok dengan sebuah token. Token adalah unit grammar dari bahasa pemrograman yang dimengerti oleh compiler.
Analyzer leksikal juga menghapus karakter whitespace, komentar, dan kesalahan dari input.
Tahap 2: Analisis sintaksis
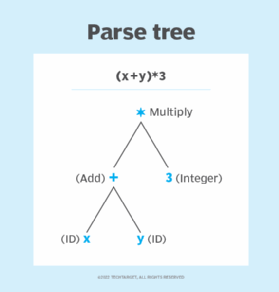
Tahap ini memeriksa struktur sintaks dari input, menggunakan struktur data bernama *parse tree* atau *derivation tree*. Analyzer sintaksis menggunakan token untuk membangun pohon parse yang menggabungkan grammar bahasa pemrograman dengan token dari input. Jika sintaks tidak sesuai, maka akan dilaporkan sebagai syntax error.
Tahap 3: Analisis semantik
Analisis semantik memverifikasi pohon parse terhadap simbol-simbol yang ada di *symbol table* dan mengecek apakah semuanya konsisten secara semantik. Proses ini juga dikenal sebagai analisis kontekstual. Cek yang dilakukan termasuk pengecekan tipe data, label, dan alur kontrol.
Misalnya kode berikut:
float a = 30.2; float b = a*20
maka analyzer akan memperlakukan 20 sebagai 20.0 sebelum melakukan operasi.
Beberapa referensi hanya menyebut tahap analisis sintaksis sebagai parsing karena di tahap inilah pohon parse dibuat. Mereka tidak memasukkan analisis leksikal dan semantik.
Apa saja jenis parser utama?
Saat sebuah bahasa pemrograman dibuat, penciptanya harus menentukan serangkaian aturan. Aturan-aturan inilah yang membentuk grammar untuk menyusun pernyataan yang valid dalam bahasa tersebut.
Berikut ini contoh aturan grammar untuk bahasa fiksi sederhana yang hanya berisi beberapa kata:
<kalimat> ::= <subjek> <kata kerja> <objek>
<subjek> ::= <artikel> <kata benda>
<artikel> ::= the | a
<kata benda> ::= dog | cat | person
<kata kerja> ::= pets | fed
<objek> ::= <artikel> <kata benda>
Dalam bahasa ini, sebuah kalimat harus mengandung subjek, kata kerja, dan objek dalam urutan tersebut. Parsing akan mengecek apakah input yang diberikan pengguna sesuai dengan aturan grammar. Ada dua jenis utama parser:
- Top-down parser. Dimulai dari aturan di atas seperti <kalimat> ::= <subjek> <kata kerja> <objek>. Misalnya, input “The person fed a cat”, parser akan memulai dari aturan pertama dan mengecek secara berurutan apakah tiap bagian sesuai aturan yang ada.
- Bottom-up parser. Dimulai dari aturan paling bawah. Misalnya dimulai dari mengenali <objek>, lalu naik ke <kata kerja>, dan seterusnya hingga sampai ke <kalimat>.
Secara sederhana, top-down parser mulai dari simbol awal grammar dan menuruni pohon parse. Bottom-up parser mulai dari input dan membangun pohon ke atas hingga mencapai aturan utama.
Selain dua jenis itu, ada juga dua jenis derivasi dalam grammar, yaitu:
- LL parser. Membaca input dari kiri ke kanan dan menggunakan derivasi kiri (leftmost derivation). LL parser memperluas elemen paling kiri dari pohon parse untuk membentuk string yang valid.
- LR parser. Membaca input dari kiri ke kanan tapi menggunakan derivasi kanan (rightmost derivation). LR parser memperluas elemen paling kanan dari pohon parse.
Ada juga jenis parser lain, seperti:
- Recursive descent parser. Menggunakan metode backtracking setelah setiap titik keputusan untuk memastikan akurasi. Termasuk dalam top-down parser.
- Earley parser. Dapat mem-parse semua grammar kontekstual bebas (context-free grammar), tidak seperti LL dan LR.
- Shift-reduce parser. Melakukan operasi shift dan reduce pada input string. Setiap tahapan akan mengurangi bagian string menjadi aturan grammar sampai semua sudah diperiksa.
Teknologi apa saja yang menggunakan parsing?
Parser digunakan saat ada kebutuhan untuk merepresentasikan input dari source code ke dalam struktur data supaya bisa dicek kesesuaiannya dengan aturan sintaks. Bahasa pemrograman dan teknologi lainnya menggunakan parsing untuk keperluan ini.
Bahasa pemrograman. Parser digunakan dalam semua bahasa pemrograman tingkat tinggi, seperti: