Apa itu dimension table?
Dalam dunia data warehousing, dimension table atau tabel dimensi adalah tabel database yang berisi atribut yang menjelaskan fakta-fakta pada fact table. Tabel ini merupakan bentuk fisik dari sebuah dimensi sesuai dengan rancangan model dimensional.
Model dimensional berfungsi sebagai cetak biru (blueprint) dalam menyusun struktur data warehouse supaya performa query-nya maksimal. Dimensi adalah inti dari model ini karena memberikan informasi referensi tentang sekumpulan kejadian yang bisa diukur, atau yang disebut dengan fakta, yang disimpan di satu atau lebih fact table. Informasi deskriptif pada dimensi inilah yang memungkinkan pengguna bisa menyaring dan mengkategorikan data fakta untuk menjawab pertanyaan bisnis secara bermakna.
Data warehouse mengimplementasikan atribut deskriptif dari dimensi ini dalam bentuk kolom-kolom di dimension table. Gambar 1 di bawah ini menunjukkan contoh struktur data warehouse sederhana yang punya empat dimension table (biru) dan satu fact table (hijau). Fact table tersebut terhubung ke semua dimension table melalui relasi foreign key. Salah satu contohnya adalah relasi ke tiga tanggal berbeda dari dimensi waktu untuk mencatat berbagai tanggal yang terkait dengan transaksi penjualan.
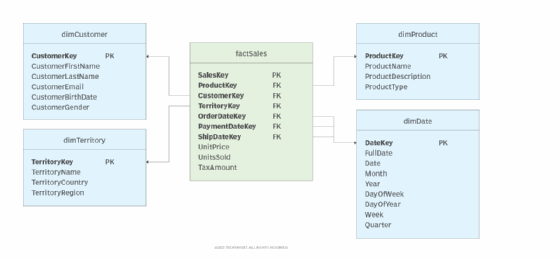
Berkat hubungan antara fact table dan dimension table, atribut-atribut dari dimensi bisa menjelaskan fakta-fakta pada fact table penjualan. Misalnya, bisa diketahui informasi tentang pelanggan, produk, wilayah, dan tanggal dari setiap transaksi. Dari sinilah data bisa dimanfaatkan untuk pengambilan keputusan bisnis yang tepat.
Contoh konkret: kita bisa bikin laporan berapa banyak pelanggan dari Amerika Utara usia 35-45 tahun yang beli printer laser di tahun 2022. Bahkan, beberapa dimension table seperti dimDate biasanya berisi data hierarkis, yang bisa dipecah jadi lebih rinci seperti per tahun, kuartal, bulan, minggu, bahkan hari.
Struktur dimension table
Dimension table pada dasarnya adalah tabel dalam database seperti MySQL, SQL Server, atau PostgreSQL. Struktur umumnya terdiri dari beberapa kolom dan baris, di mana satu kolom berperan sebagai primary key (kunci utama), dan kolom lainnya menyimpan atribut yang didefinisikan dalam dimensi menurut model data yang digunakan.
Sementara itu, fact table di data warehouse punya beberapa foreign key yang mengacu pada primary key dari dimension table yang bersangkutan.
Fact table biasanya juga menyimpan data kuantitatif atau metrik pengukuran. Relasi antara fact table dan dimension table memungkinkan kita untuk melakukan “slice and dice” terhadap data — alias menyusun ulang data berdasarkan kombinasi atribut yang berbeda untuk menjawab berbagai pertanyaan bisnis.
Primary key dalam dimension table bisa berupa natural key ataupun surrogate key. Namun, kebanyakan sistem lebih menyarankan penggunaan surrogate key karena bentuknya lebih simpel (biasanya berupa angka integer), sehingga proses join antar tabel jadi lebih cepat dan efisien. Surrogate key juga lebih fleksibel kalau datanya berasal dari berbagai sumber. Umumnya, key ini dikelola otomatis oleh sistem database.
Kebanyakan dimension table sudah dalam bentuk denormalisasi agar lebih optimal buat beban kerja yang dominan baca data, khas di data warehouse. Berbeda dengan sistem transaksi biasa yang butuh struktur normalisasi tinggi karena sering melakukan baca-tulis data. Denormalisasi bikin proses analisis data lebih simpel dan efisien.
Skema star dan snowflake
Denormalisasi sangat penting dalam struktur star schema seperti di Gambar 2. Di skema ini, satu fact table utama langsung terhubung ke banyak dimension table, tanpa perlu ada tabel perantara. Dengan dimension table yang sudah didenormalisasi, query jadi lebih simpel, join lebih sedikit, dan performa query jadi lebih cepat.
Pendekatan lainnya adalah snowflake schema, yang merupakan versi lanjutan dari star schema. Di sini, beberapa dimension table bisa dihubungkan ke tabel dimensi lain untuk membentuk struktur yang lebih ternormalisasi. Misalnya, di Gambar 2, tabel dimProduct bisa dinormalisasi dengan memisahkan tipe produk ke tabel lain, lalu dihubungkan lewat primary key.
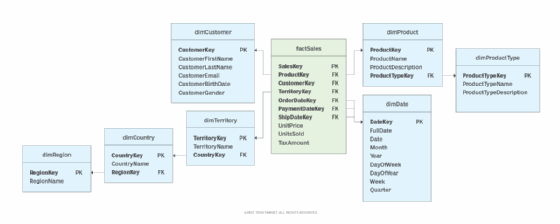
Contoh lain, dimTerritory juga bisa dinormalisasi menjadi tabel region dan country, lalu masing-masing dihubungkan dengan primary key-nya. Bahkan, ada juga snowflake schema yang menormalisasi dimDate, tergantung kebutuhan dan cara penggunaan datanya.
Dengan skema snowflake, pengulangan data (redundansi) jadi lebih sedikit, apalagi kalau ada struktur hierarkis seperti wilayah > negara > teritori. Namun, karena tabelnya jadi lebih banyak dan join makin kompleks, performa query bisa sedikit menurun.
Pelajari lebih lanjut tentang opsi deployment data warehouse dan studi kasus penggunaannya. Pahami juga perbedaan antara dimension table dan fact table, serta kelebihan dan kekurangan antara data warehouse on-premises dan cloud.