Apa itu fault management?
Fault management adalah komponen dalam network management yang berfungsi untuk mendeteksi, mengisolasi, dan memperbaiki masalah pada jaringan. Jika diimplementasikan dengan baik, fault management dapat menjaga konektivitas, aplikasi, dan layanan tetap berjalan optimal, menyediakan fault tolerance, serta meminimalisasi downtime. Fault management systems adalah platform atau tools yang memang dirancang khusus untuk tujuan ini.
Fault biasanya muncul akibat malfungsi atau event yang mengganggu, menurunkan kualitas, atau bahkan memblokir delivery layanan. Contoh fault antara lain kerusakan hardware, putusnya koneksi, atau perubahan status port. Setelah platform fault management mendeteksi fault, sistem akan memberikan notifikasi ke administrator — serta pihak lain yang berwenang — melalui alarm atau alert.
Administrator jaringan bisa melihat notifikasi ini lewat GUI pada fault management system. Banyak platform juga bisa meneruskan alert via email, SMS, atau aplikasi mobile. Selain itu, fault management system dapat dikonfigurasi agar secara otomatis memperbaiki atau mencegah event tertentu dengan menggunakan program atau script.
Fault management merupakan salah satu komponen dari FCAPS (fault management, configuration, accounting, performance, dan security), yaitu framework network management yang ditetapkan oleh International Organization for Standardization (ISO).
Fungsi penting dalam fault management
Network fault management mencakup berbagai fungsi untuk menjaga agar jaringan tetap berjalan. Fault management system biasanya melakukan hal-hal berikut:
- Mendefinisikan threshold untuk kondisi yang berpotensi gagal.
- Melakukan monitoring status sistem dan tingkat penggunaan secara terus-menerus.
- Melakukan scanning secara berkala terhadap ancaman, seperti virus dan Trojan.
- Menyediakan diagnostic umum.
- Mengontrol elemen sistem secara remote, termasuk workstation dan server, dari satu lokasi.
- Memberikan notifikasi ke administrator dan user terkait malfungsi yang akan terjadi atau yang sudah terjadi.
- Melacak lokasi malfungsi potensial maupun aktual.
- Secara otomatis mengoreksi kondisi yang berpotensi menimbulkan masalah.
- Secara otomatis memperbaiki malfungsi.
- Mencatat secara lengkap status sistem dan semua tindakan yang dilakukan.
Jenis-jenis fault management
Ada dua jenis utama network fault management: active dan passive.
Active fault management
Active fault management menggunakan berbagai tools, seperti ping atau pengecekan port TCP/UDP, untuk terus melakukan query ke perangkat dan menentukan statusnya. Ibaratnya seperti orang yang terus bertanya, “Apa kabar?” ke semua orang di ruangan dalam interval tertentu. Dengan pendekatan ini, fault management system bisa mengidentifikasi dan memperbaiki masalah secara real time, bahkan sebelum masalah benar-benar muncul. Trade-off-nya adalah menambah network chatter (lalu lintas tambahan di jaringan).
Passive fault management
Passive fault management memonitor lingkungan jaringan untuk mendeteksi event yang mengindikasikan adanya fault atau kegagalan. Informasi ini bisa berasal dari error log atau trap Simple Network Management Protocol (SNMP), dan sumber lainnya. Ibaratnya seperti orang yang diam menunggu sampai ada yang minta bantuan. Pendekatan ini lebih hemat resource, tetapi kelemahannya adalah fault mungkin baru terdeteksi setelah terlambat.
Proses fault management
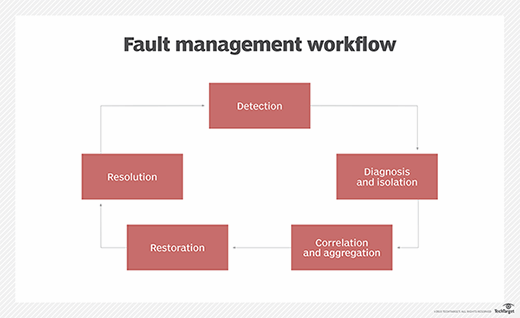
Proses fault management pada platform komersial mungkin sedikit berbeda antar vendor, tetapi umumnya sistem mengikuti lifecycle yang sama:
- Fault detection. Sistem mendeteksi bahwa service delivery terganggu atau performanya menurun.
- Fault diagnosis and isolation. Sistem mengidentifikasi sumber fault, misalnya kerusakan komponen atau mati listrik, serta lokasinya dalam topologi jaringan.
- Event correlation and aggregation. Karena satu fault bisa menimbulkan banyak alarm, fault management system biasanya mengelompokkan event terkait untuk administrator dan menyediakan root cause analysis.
- Restoration of service. Network management system mengeksekusi script atau program yang sudah dipreconfig untuk mengembalikan layanan secepat mungkin.
- Problem resolution. Sistem memperbaiki, memperbarui, atau mengganti sumber fault. Dalam beberapa kasus, intervensi manual mungkin tetap dibutuhkan tergantung penyebabnya.